一. 本章涉及到的专业名词和概念
(这些概念什么意思,是属于哪一级别的概念,属于哪方面的概念)
概念级别:
- L0 原子概念:从面试角度看,不会再往下分了。
- L1 基础概念:涉及到2个以上原子概念或者可以往下分析的
- L2 综合概念:涉及到2个以上基础概念或者是一个topic的形式
- L3 大概念:涉及到2个以上综合概念,在往上就比较模糊了。
| 名词 | 解释 | 概念级别 | 概念分类 | 概念相关面试问题 |
|---|---|---|---|---|
| 线性回归 | 输出是一个连续值,适用于回归问题,单层神经网络。 | L0 | 模型 | |
| softmax回归 | 输出是离散值,适用于分类问题,单层神经网络。 | L0 | 模型 | |
| 单层神经网络 | 没有隐藏层时,输入层没有计算,只有输出层做计算,这种叫做单层神经网络 | L1 | 模型 | |
| 多层感知机 | 含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。 | L1 | 模型 | |
| 广播机制 | 先适当复制元素使这两个 Tensor 形状相同后再按元素运算 | L0 | pytorch语法 | |
| 训练误差 | 训练数据集上表现的误差。 | L0 | 模型训练 | |
| 泛化误差 | 测试数据集上表现的误差。 | L0 | 模型训练 | |
| 欠拟合 | “模型无法得到较低的训练误差。” | L0 | 模型训练 | |
| 过拟合 | “训练误差远小于它在测试集上的误差。” | L0 | 模型训练 | |
| 权重衰减 | “等价于L2范数正则化。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。L2范数正则化在模型原损失函数基础上添加L2范数惩罚项,从而得到训练所需要最小化的函数。L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。” | L1 | 模型训练 | |
| 丢弃法 |  |
L1 | 模型训练 | |
| 正向传播 | L1 | 模型 | ||
| 反向传播 | L1 | 模型 |
二、深度学习模型的基本要素
- 模型:输入是数据,输出是预测,和真实的结果有一点误差。由参数(权重,偏差,这两个都是标量)组成。
- 模型训练:通过数据来寻找特定的模型参数值,使得模型在数据上的误差尽可能小。涉及到
训练数据:训练集,样本,标签,特征。
损失函数:衡量预测值和真实值之间的误差,通常会选择一个非负数,数值越小,误差越小。
优化算法:误差最小化问题可以用公式表达的叫做解析解,没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值,叫做数值解。最常用的是小批量随机梯度下降。 - 超参数:人为设定,非模型学习的参数,比如批量大小和学习率。(这两个现在也有技术 自己学习)
- 模型预测:模型推断,模型测试。
三、深度神经网络的构建步骤
- 生成数据集
- 读取数据集
- 初始化模型参数
- 定义模型
- 定义损失函数
- 定义优化算法
- 训练模型
- 预测结果
四、代码学习-pytorch的知识
本章用到的相关pytorch函数见表格function
关于TensorDataset
TensorDataset 是构造数据集的类,可以构造自己的数据集类,需要继承这个类关于nn.module
nn.module 构造模型的类
继承nn.Module,必须实现init() 方法和forward()方法。其中init() 方法里创建子模块,在forward()方法里拼接子模块。class LeNet(nn.Module): # 子模块创建 def __init__(self, classes): super(LeNet, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16*5*5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, classes) # 子模块拼接 def forward(self, x): out = F.relu(self.conv1(x)) out = F.max_pool2d(out, 2) out = F.relu(self.conv2(out)) out = F.max_pool2d(out, 2) out = out.view(out.size(0), -1) out = F.relu(self.fc1(out)) out = F.relu(self.fc2(out)) out = self.fc3(out) return outnn的组件见表格 nn module
关于torch.nn.Sequential torch.nn.Module nn.ModuleList
torch.nn.Sequential 和 torch.nn.Module 后者需要自己实现forward函数。使用torch.nn.Module,我们可以根据自己的需求改变传播过程,如RNN等。如果你需要快速构建或者不需要过多的过程,直接使用torch.nn.Sequential即可。
nn.ModuleList 是包含子模块的list,把不同的module放入后,可以像python list一样迭代
和sequential的不同点是 没有实现forward函数,需要自己实现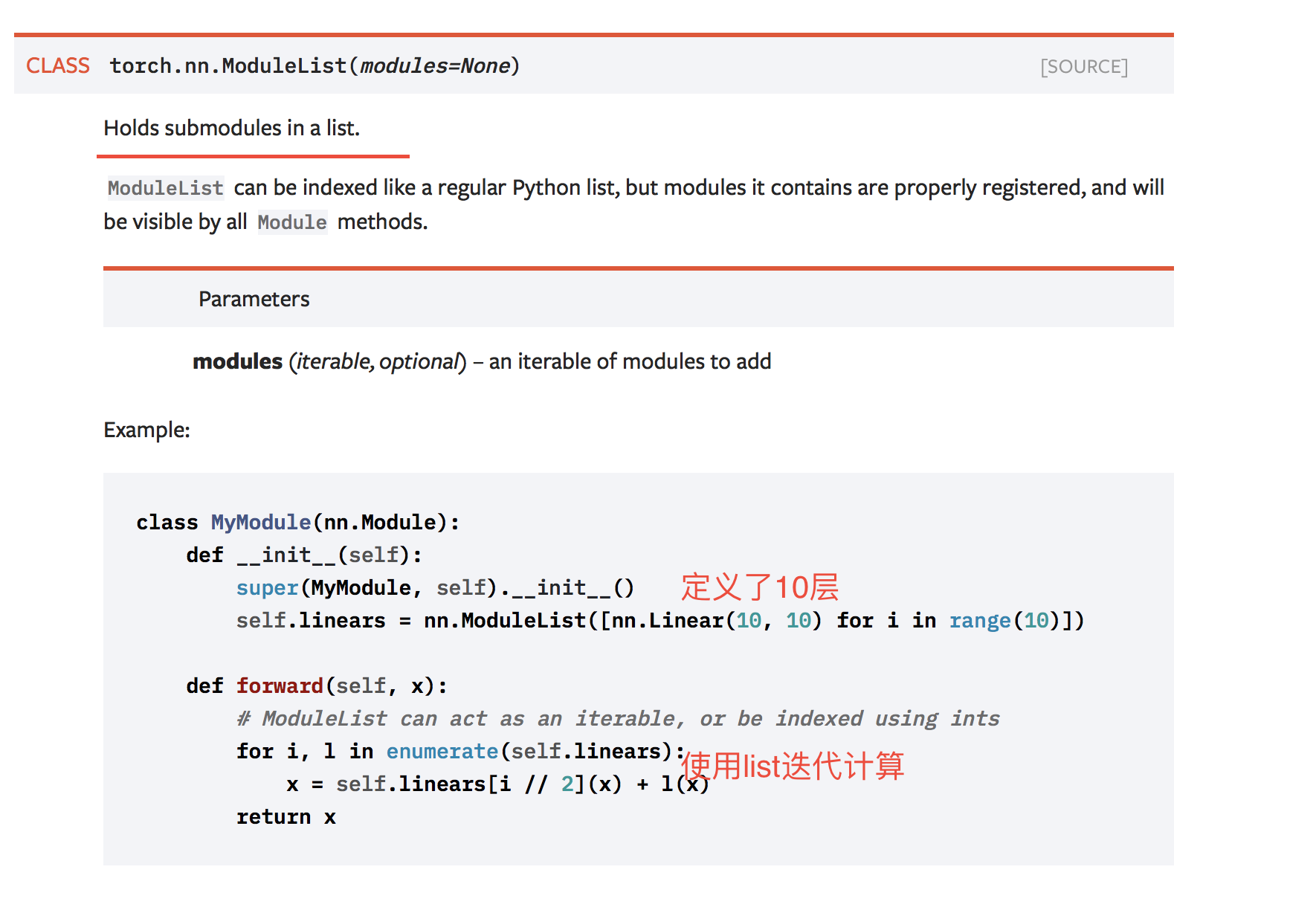
并且nn.ModuleList里面的顺序并不代表 网络实际的顺序,只是把一些网络层放到一起了关于nn.BatchNorm2d
机器学习中,进行模型训练之前,需对数据做归一化处理,使其分布一致。在深度神经网络训练过程中,通常一次训练是一个batch,而非全体数据。在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。BatcNormalization强行将数据拉回到均值为0,方差为1的正太分布上,一方面使得数据分布一致,另一方面避免梯度消失



