本章概念:
隐藏变量(隐藏状态):
循环神经网络:
语言模型:
一、语言模型
1. 语言模型用来干什么?
- 自然语言文本可以看作一段离散的时间序列。假设一段长度为T的文本中的词依次为w1, w2, …,wT,那么对于每个词wt都可以看作是时间步t的标签。时间步是t就代表第t个词。语言模型将计算下面一段文本序列的概率:
P(w1,w2,…,wT) - 语言模型可以提升语音识别和机器翻译的性能。比如语音识别,有一段“厨房里食油用完了”的语音,有可能输出 “厨房里食油用完了”和“厨房里石油用完了”这两个读音完全一样的文本序列。这个是时候需要判断哪个文本序列的概率大,最终输出概率大的文本序列。
2. 语言模型的计算方法
- 原始方法
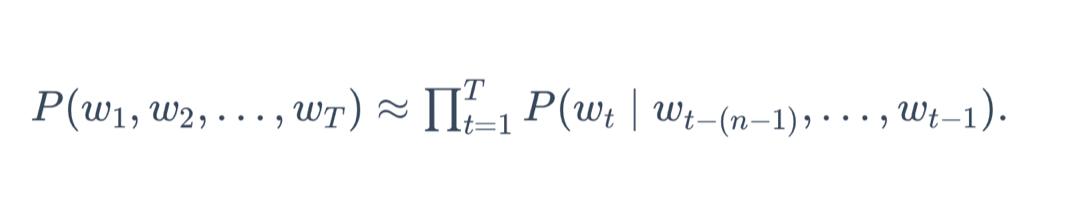
- 马尔科夫假设的方法(n元语法)
前提假设:每个词出现在文本序列的概率,只和它前面n-1个词相关
上述公式改写为
举例,长度为4的文本序列,一元,二元,三元的概率计算方法为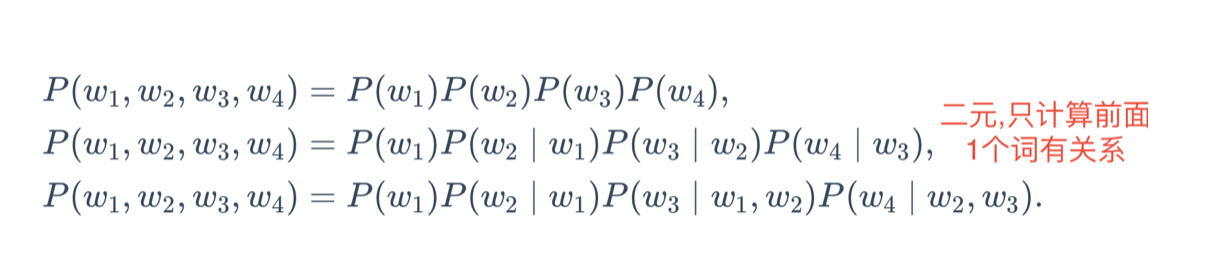
弊端:n比较小时不准确:比如说一元的时候,“你走先”,“你先走”计算的概率一样大,实际上后面的概率要打。
N比较大时,需要存储大量的词频和相邻词频频率。
二、循环神经网络能解决的问题
N元语法中,词wt的计算值考虑了前面n-1个词。如果要增大n,那么模型参数将呈指数级增长。
Rnn并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。这样就能提高计算的准确性,又不会指数级的增大参数数量。
三、循环神经网络的构造
在原来的多层感知机上,保存隐藏状态,供下一次的隐藏层计算使用。
多层感知机的网络结构
有隐藏状态的时候,隐藏层的计算方式,如下:
批量样本X:个数n,特征个数d
隐藏层单元个数:h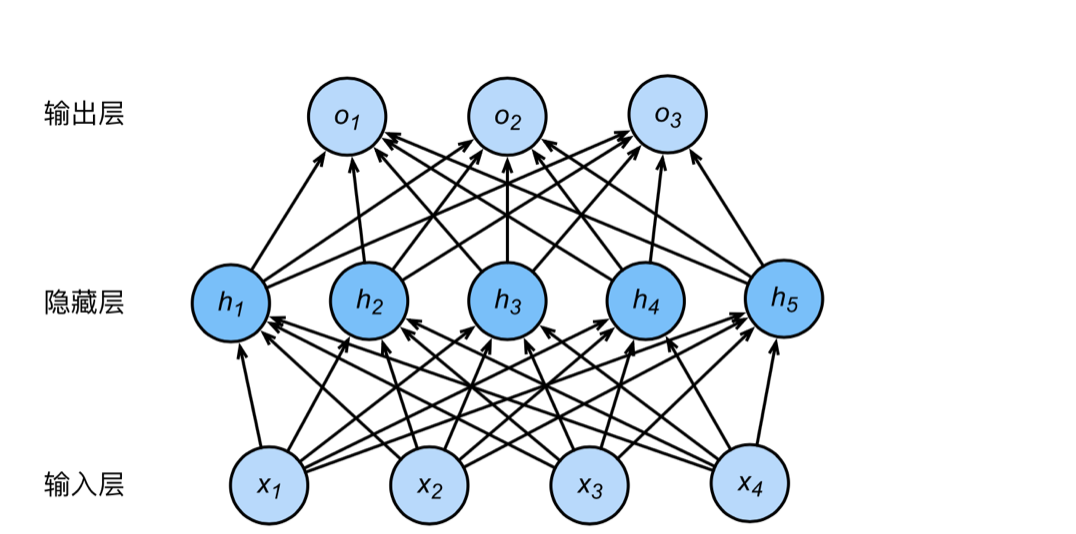
输出层单元个数:q
激活函数:ϕ
t时间步的时候,隐藏层的输出改为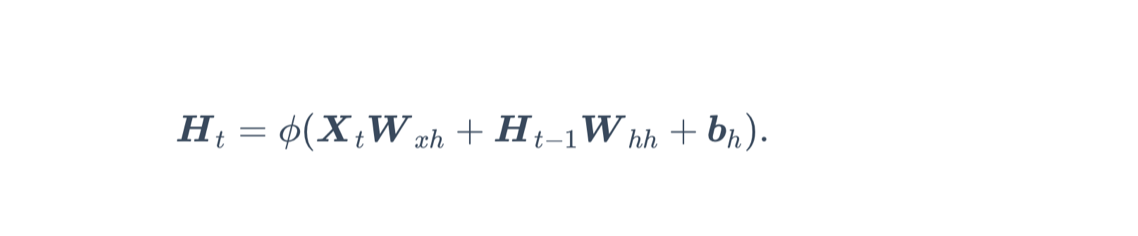
输出层的计算和之前一样: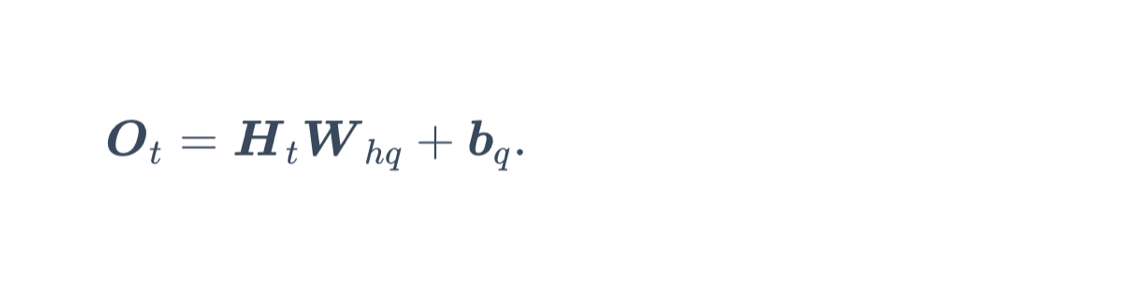
Ht-1是上次隐藏层的输出,类似于递归函数,每一次计算都需要用到上一次的输出结果,自然也需要保存上一次的结果Ht-1,这些保存的结果被称为隐藏变量。
Q:这里的时间步要怎么理解?
A:多层感知机中,每次计算一个批量,每一次计算都可以算做一个时间步的计算。时间步t可以理解成第t次计算。
Q:怎么理解隐藏变量?
A:这个变量没有显示出来(计算完Ht,隐藏层输出是Ht,并没有网络表示Ht-1,因为它是上一回表示的,这次轮到下一位了),所以是隐藏的,但是我们要存储起来。
Q:隐藏变量的作用?
A:因为隐藏变量的每次计算,都和上一步的计算结果有关系(可以理解成递归函数或者递归序列 2 4 6 8 10 每一项都是上一项的值加2,知道第一项可以计算第n项,计算第n项,必须先计算第n-1项),所以这里的隐藏变量能够捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或者记忆一样。
网络结构可以理解成下面的图: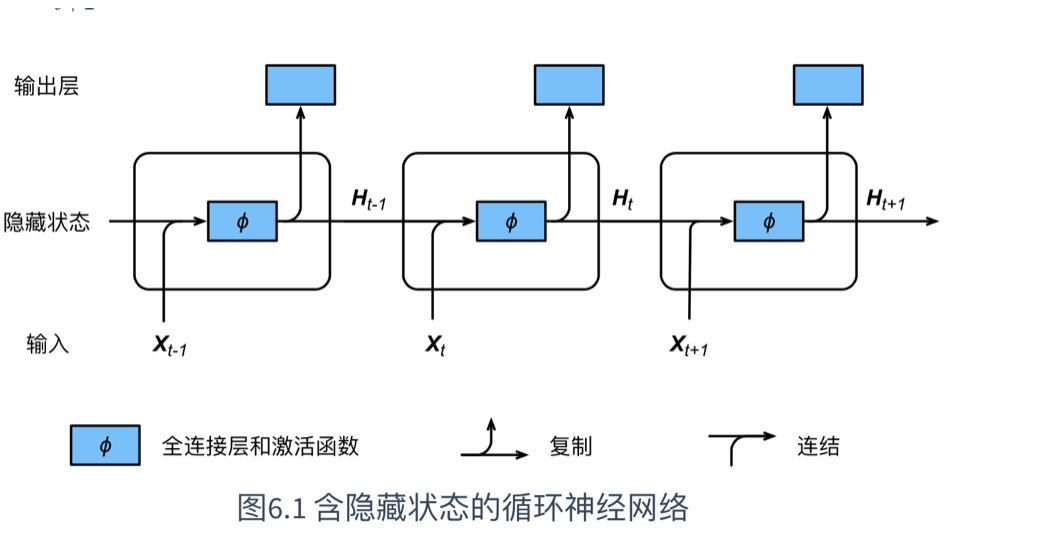
展示了循环神经网络在3个相邻时间步的计算逻辑。在时间步t,隐藏状态的计算是由当前的输入Xt和上一次的结果Ht-1共同决定的。
Q:循环神经网络怎么避免参数指数级增长?
A:对于每个时间步t,计算隐藏层输出Ht时,所用到的权重参数Whh,都是一样的。这样无论多长的输入,网络参数的规模都一样,并没有增长。
四、循环神经网络产生语言模型
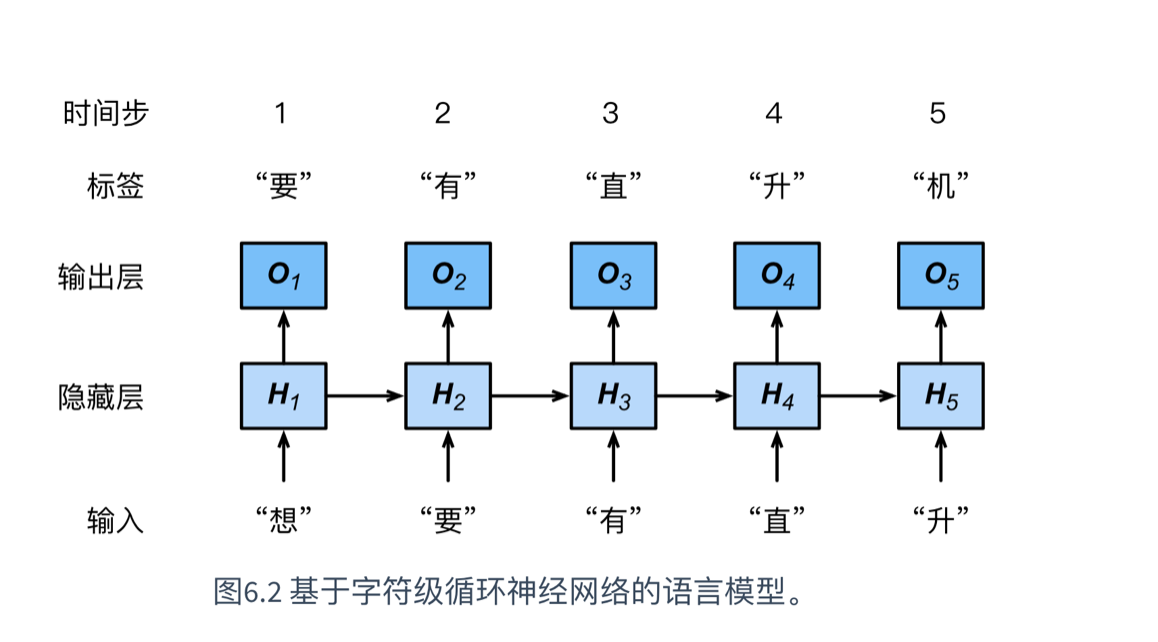
文本序列为:“想要有”
当时间步为3时,输入为“有”,但是输出O3取决于文本序列“想”“要”“有”,时间步3的损失取决于生成下一个词的概率分布与该时间步的标签“直”。
这种网络可以基于当前和过去的字符来预测下一个字符,也就是得到了概率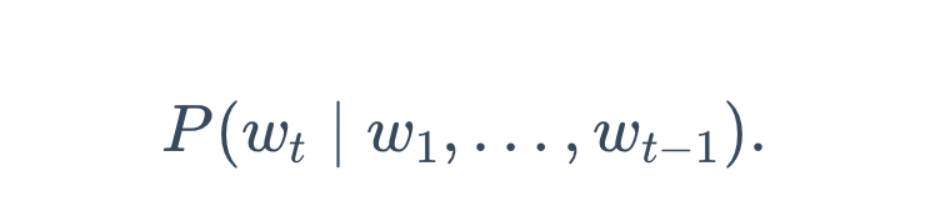
这样就能计算整个序列的概率了。



