系统概览
一、针对的需求
很多社交媒体平台(Social Media Platform,简称SMP)都存在创作者拉新的需求,通常是需要获取某个垂类下的创作者,比如说:
PM:我们主打搞笑社区,希望获取ins上的搞笑作者,让他们在我们的社媒平台进行创作;
PM:站内科技方面的内容较少,希望获取ytb上的科技类的创作者,让他们也在我们这发视频;
。。。
这一类的需求统统归为线索挖掘需求。通常来说,通过一定的技术手段,获取竞品平台上的创作者的一系列活动被称为线索挖掘,这些技术手段和相关的活动组成了线索资源挖掘系统(Clue Resource Mining System,简称CRMS)。很明显,CRMS有如下特点:
- 竞争性:我们是针对竞品去挖掘的,竞品上都没有的话,我们也挖不到,说白了就是挖对手的墙角,最终的目的就是这个创作者离开了竞品,来到了我们的平台,当然CRMS只负责把创作者找出来。
- 筛选机制:一般的用户是不值得获取的,我们想得到有创作能力,有影响力的创作者。
- 针对性:我们一般是针对某个垂类去挖掘,比如挖掘幽默类的创作者,挖掘擅长健身的创作者等等。
- 可触达:我们一般要求最终的线索是可以触达的,即运营是可以通过某种正常方式联系上创作者的,不然话,运营联系不到他们,就不能和他们沟通,我们找了也是白费劲。
二、社交媒体的特点
当PM提了上述需求后,RD如果很容易就答应PM,那就上当了,这个活是不好干的,你假如这样回应:
RD:好啊,我去ins上把这些搞笑达人都抓取下来,分分钟的事,下午就给你(话说你怎么知道ins上哪些用户是搞笑达人,你在搞笑吗!!!)
RD:好的,我去ins上把发搞笑表情的用户都抓取下来,可以了吧,明天给你(话说你怎么知道ins上哪些人发过表情包,你有ins的DB吗,有它们的DB,我自己上sql就行了,你在搞笑吗!!!)
RD:好吧,我去ins上抓取一批,然后把简介里面有提到搞笑的用户抓取下来,下周给你(话说简介⾥说⾃⼰是comedy、funny就⾏了?普通⼈也能这么介绍⾃⼰吧?)
。。。
我们仔细分析下这个任务后,就会发现简单的逻辑完成不了这个需求。其实这些都是由于SMP上的资源并不是可以直接获取造成的,比如说:
如ins ytb tw这些全球性的SMP基本上不支持按照地区筛选用户;
SMP基本不会公开用户/内容的分类标签;
SMP肯定不支持按照是否有联系方式筛选数据;
。。。
SMP一般都具有下面的特点:
- 封闭性:自己的创作者负责创作内容,由自己的用户消费这些内容,形成循环;
- 排它性:不接受其他平台的内容,使用各种手段,吸引和限制用户在自己的平台;
- 垄断性:在某个领域形成市场领导地位,有了用户基础后,获取暴利;
这些特点使得我们没有办法直接从竞品上获取我们想要的创作者,我们需要其他方法达到目的。
三、挖掘风险
PII(personalidentificationinformation)风险了解下,采集竞品上的这类内容往往存在着给公司和平台造成剽窃等舆论压力和非法采集信息等法律风险。当采集内容涉及到PII时,需要及时和PR部门沟通。
四、可行的方法-CRMS 0.0.1版本
需求这么难,还有进号子的风险,那看来这个需求砍掉算了吧,但砍需求,是打工人该说的话吗。。。(心里一万头草泥马)
我们分析下SMP上可用的资源有哪些呢?
- 竞品上用户的昵称/简介/粉丝量/关注量/发⽂量/发⽂内容/评论及数量/点赞及数量 都是公开的,这些是不存在法律风险的。
哇。。。你看我们有这么多资源可以用呢 - 专业的创作者一般会在主页显示联系方式,他们也希望自己的作品散播到更多的平台上,让更多的人看到他们。
所以我们是在帮助创作者。(心里得到一丝安慰。。。,我不是在犯罪。。。我是个好人。。。)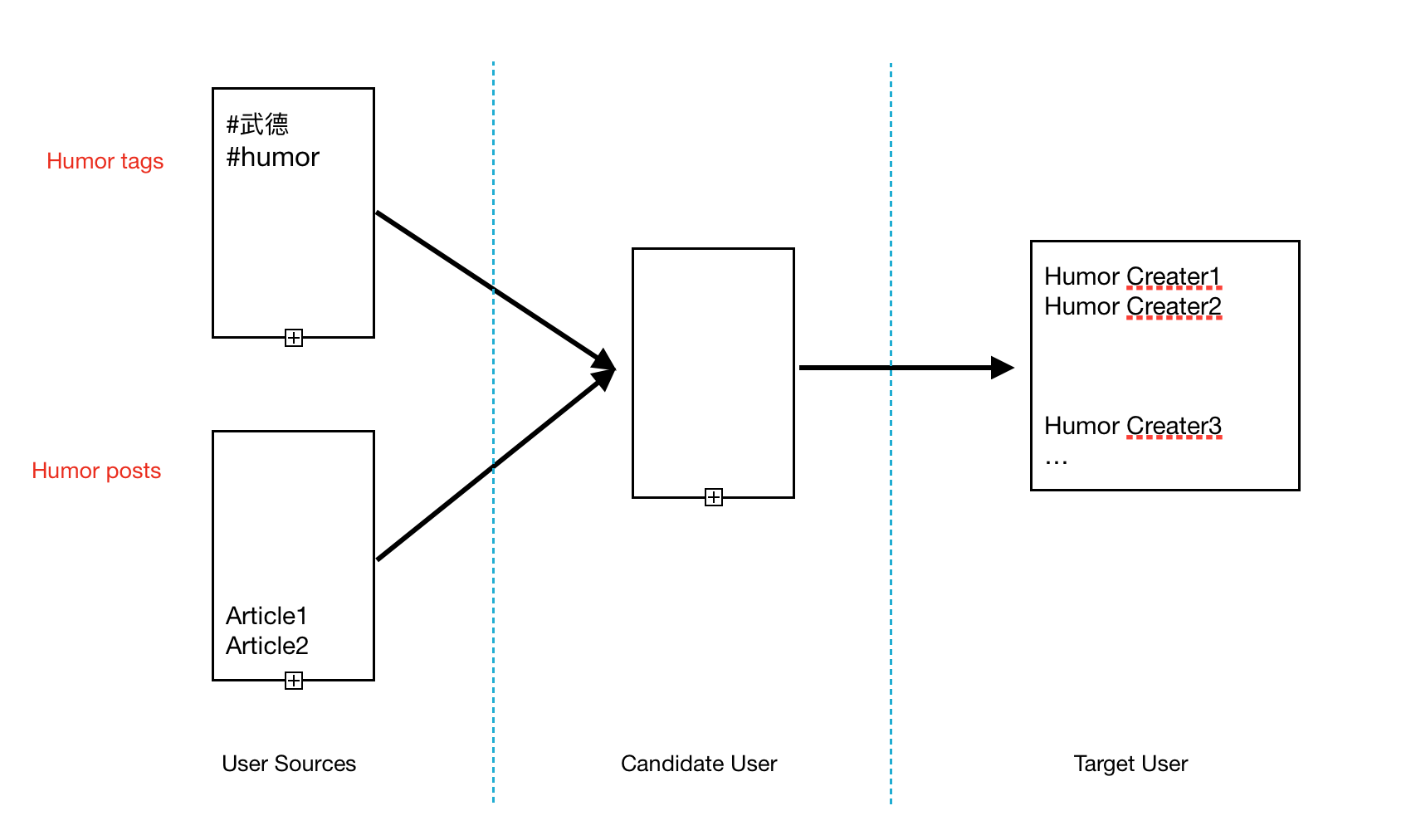
经过上面的分析,就产生了下面的方法,来解决这个问题。
我们假设PM的需求是:“我们主打搞笑社区,希望获取ins上的搞笑作者,让他们在我们的社媒平台进行创作;”,为了满足这个需求,构建了CRMS系统的0.0.1版本。
这个版本有3部分构成,分别是:
1、User Sources:这部分是为了召回一些候选的用户;
2、Candidate Users: 这部分是为了筛选幽默类的用户;
3、Target User:这部分是为了存储最终想要的幽默类用户;
下面我们分别阐释系统的三个部分:
首先、UserSources部分,由两部分组成,一部分是比较幽默的tag,这些tag下面往往会有很多幽默类的文章;另一部分呢 是幽默类的文章。
怎么召回用户呢?简单的办法就是,根据tag下面的文章,把这些文章的作者都抓取下来;把幽默类的文章的作者也抓取下来。这样我们就得到了一批候选用户。
其次、Candidate Users部分,它主要是根据用户的发文和用户的基本资料,识别出哪些用户是幽默类的用户。
怎么识别一个用户是不是幽默类用户呢?首先我们需要一个模型去判断一篇文章是不是属于幽默类文章,然后如果用户的发文大部分都是幽默类文章,那么我们就可以认定这个用户是幽默类文章。
最后,Target Users部分,它主要是记录每个用户的识别结果,如果是幽默类用户的话,就把这个用户存储下来,并且还要拿到用户的联系方式。
经过上面的步骤,我们就能很好地完成这个需求了
五、总结
这部分主要是介绍了CRMS系统要解决的问题和系统本身的要求,并且构建了一个初级的版本,下一部分我们会更深入一点,并在这个初级版本上进行升级。



